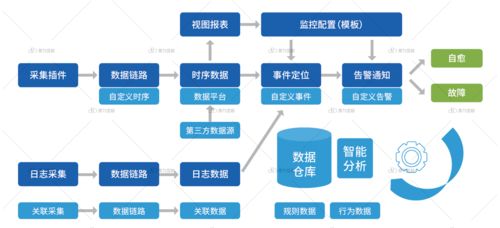
微服務開發中的數據架構設計
隨著軟件開發領域的不斷演進,微服務架構已成為現代應用開發的主流模式之一。在微服務架構中,數據架構設計是確保系統可擴展性、一致性和性能的關鍵環節。本文將探討微服務開發中的數據架構設計原則、常見模式以及最佳實踐,幫助開發團隊構建高效、可靠的數據層。
一、微服務數據架構設計原則
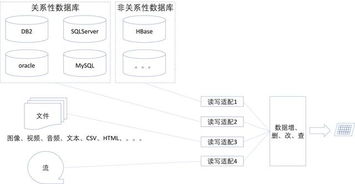
- 數據自治:每個微服務應擁有其專屬的數據存儲,避免服務間直接共享數據庫,以降低耦合度。例如,訂單服務使用獨立的訂單數據庫,用戶服務管理用戶數據,確保服務的獨立部署和擴展。
- 數據一致性:在分布式環境中,數據一致性是挑戰。可通過事件驅動架構(如發布-訂閱模式)或使用Saga模式實現最終一致性,避免強一致性帶來的性能瓶頸。
- 可擴展性:數據存儲應根據服務負載選擇合適的技術,如關系型數據庫用于事務密集型服務,NoSQL數據庫用于高吞吐量場景。采用分片或復制策略提升擴展能力。
- 安全與合規:數據架構需包含加密、訪問控制和審計機制,確保敏感數據(如用戶個人信息)的合規處理,遵循GDPR或行業標準。
二、常見數據架構模式
- 數據庫 per 服務模式:每個微服務使用獨立的數據庫,實現數據隔離。優點包括減少服務間依賴,但需通過API或事件進行數據同步。例如,電商系統中,庫存服務與支付服務分別維護自己的數據。
- 事件溯源模式:通過存儲事件序列而非當前狀態,實現數據追溯和重建。適用于需要審計或復雜業務邏輯的系統,如金融交易應用。
- CQRS模式(命令查詢職責分離):將寫操作(命令)和讀操作(查詢)分離,使用不同數據存儲。例如,寫操作使用關系數據庫,讀操作使用緩存或搜索引擎,以提升性能。
- 共享緩存模式:引入分布式緩存(如Redis)存儲常用數據,減少數據庫負載,提高響應速度。需注意緩存一致性問題,可通過失效策略或事件更新機制解決。
三、最佳實踐與挑戰
- 實踐建議:
- 在設計階段明確數據邊界,避免服務間數據冗余。
- 使用消息隊列(如Kafka或RabbitMQ)處理異步數據流,確保可靠的事件傳遞。
- 實施數據監控和備份策略,預防單點故障。
- 常見挑戰:
- 分布式事務管理復雜,需權衡一致性與性能。
- 數據遷移和版本控制可能引發兼容性問題。
- 團隊需具備跨數據庫技術棧的知識。
四、結論
在微服務開發中,數據架構設計不僅是技術選擇,更關乎業務敏捷性和系統可靠性。通過遵循自治、一致性和可擴展性原則,并采用合適的模式,開發團隊可以構建出適應快速變化需求的數據層。成功的數據架構應支持服務的獨立演化,同時保障數據完整性和用戶體驗。隨著云原生和AI技術的普及,未來微服務數據架構可能進一步融合智能優化和自動化管理,為軟件開發帶來新機遇。
如若轉載,請注明出處:http://m.nroup.cn/product/40.html
更新時間:2026-03-15 22:53:29